
Introduction
In this post, Let’s see what is httpx and how to use the tool. Below is the video format of the post, Check that also 👇🏾
Video
What is httpx
Httpx is a fast and multi-purpose HTTP toolkit that allows running multiple probes using the retryablehttp library.
It is designed to maintain result reliability with an increased number of threads.
In simple the httpx is used to grab the banner and the GET, POST, PUT, PATCH, DELETE, OPTION, HEAD, TAIL parameters.
Now, You should be thinking of the curl utility, Which also does the same thing, But the httpx is most popular among bug-bounty hunters and quiet good when it comes to speedy results.
Who Developed httpx
The tools are developed by an open-source community called projectdiscovery.io, Sandeep Singh the co-founder takes care of updating the tools and taking care, Not only him there are other developers who takes care of the tools.
Features in httpx
- Simple and modular code base making it easy to contribute.
- Fast And fully configurable flags to probe multiple elements.
- Supports multiple HTTP based probings.
- Smart auto fallback from https to http as default.
- Supports hosts, URLs and CIDR as input.
- Handles edge cases doing retries, backoffs etc for handling WAFs.
Advertisement
httpx Installation
1. From Binary
▶ Download latest binary from : https://github.com/projectdiscovery/httpx/releases
▶ Extract the Archive : tar -xvf httpx_[Version]_linux_amd64.tar.gz
▶ Move file to the bin : mv httpx /usr/local/bin/
▶ Check Installation : httpx -h
2. From Source
▶ httpx requires go1.14+ to install successfully. Run the following command to get the repo :
▶ GO111MODULE=on go get -v github.com/projectdiscovery/httpx/cmd/httpx
3. From Github
▶ Install go lang.
▶ Run command : git clone https://github.com/projectdiscovery/httpx.git; cd httpx/cmd/httpx; go build; mv httpx /usr/local/bin/; httpx -h
For More Info Please visit : https://github.com/projectdiscovery/httpx/
How to use httpx
Follow every example carefully by end of this post you will be very familiar with the tool and if you continuously work for 2 -4 hrs you will become a pro.
Work hard until you reach your goal let’s make hand’s wet
BY STUPID ME ????
Standard Scan
This scan just sends request and see the response code and it doesn’t do anything more than that.
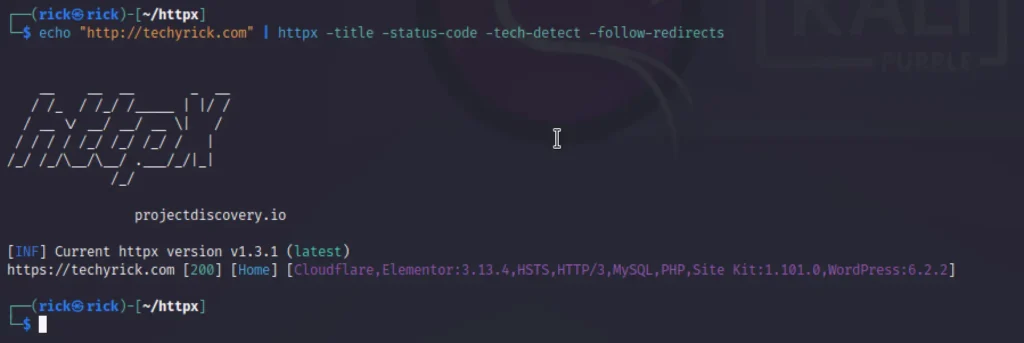
echo "http://techyrick.com" | httpx -title -status-code -tech-detect -follow-redirects
Also we can add other attributes to go more accurate results.
- -title: displays the title of the webpage
- -status-code: displays the response code. 200 being valid or OK status while 404 being the code for not found
- -tech-detect: detects technology running behind the webpage
- -follow-redirects: Enables following redirects and scans the following page too
Scanning Multiple Sites
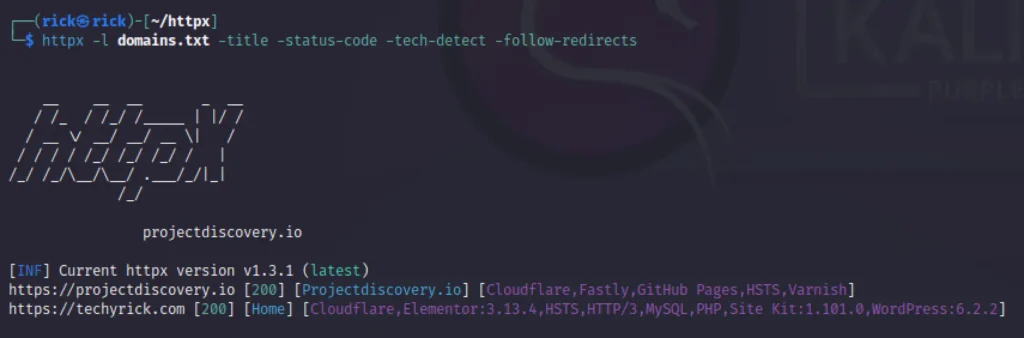
We can also scan multiple websites using the -l command with the file name. Take a look the below example.
httpx -l domains.txt -title -status-code -tech-detect -follow-redirects
Subfinder & httpx
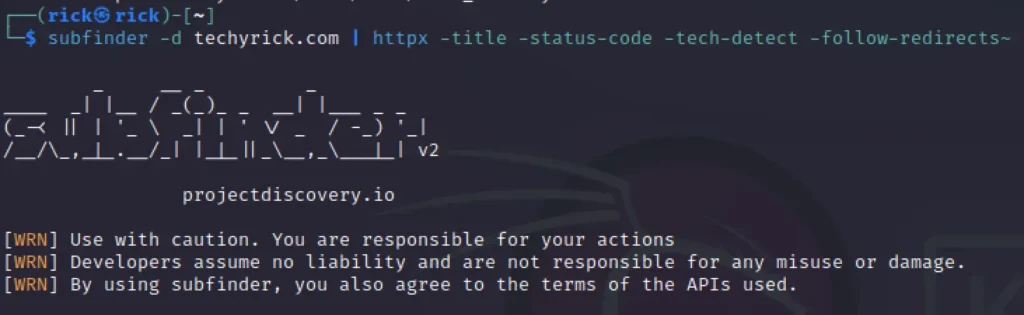
We can use subfinder along with the httpx to get awesome results, We can sort out the results very specifically.
subfinder -d techyrick.com | httpx -title -status-code -tech-detect -follow-redirects
Probing
There are various modules that can refine how a response is rendered which is called a “probe.” These help us refine scan results.
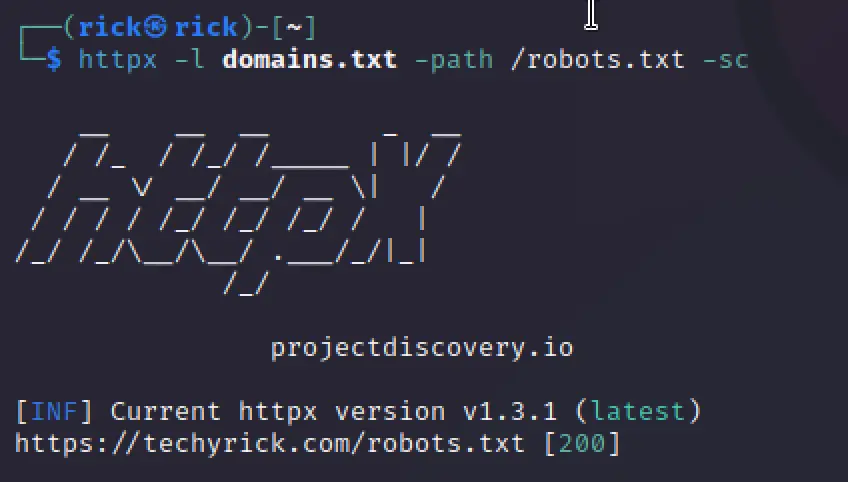
- -sc: show HTTP response status code
- -path: a specified path to check if it exists or not
httpx -l list -path /robots.txt -sc
There are various other probes that help us render better outputs
- -location: website where redirected. Here, observe how http becomes https
- -cl: displays the content length of the resulting web page
- -ct: content type of the resulting web page. Mostly HTML
echo "http://google.co.in" | httpx -sc -cl -ct -location
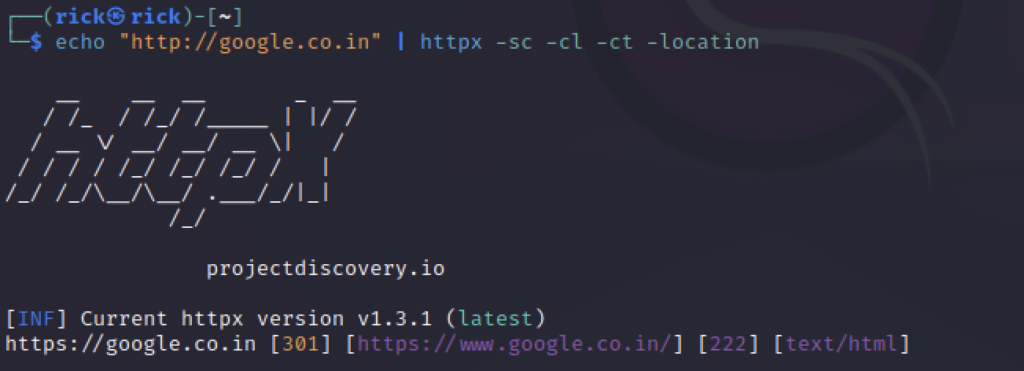
Some of the probes are really very helpful for dept analysis.
- -favicon: fetches mmh3 hash of /favicon.ico file
- -rt: shows the response time
- -server: displays the server version and build
- -hash: shows the webpage’s content’s hash
- -probe: displays the status of a single scan (success/failed)
- -ip: displays the IP of the webserver
- -cdn: displays the CDN/WAF if present
- -lc: displays the line count of scanned web page
- -wc: displays the word count of scanned web page
Filter Contents
We can also filter out the contents after saving the results in a text file, For example if you have saved the results and want to filter out 404 just try the below example ????????
cat domains.txt | httpx -sc -fc 200
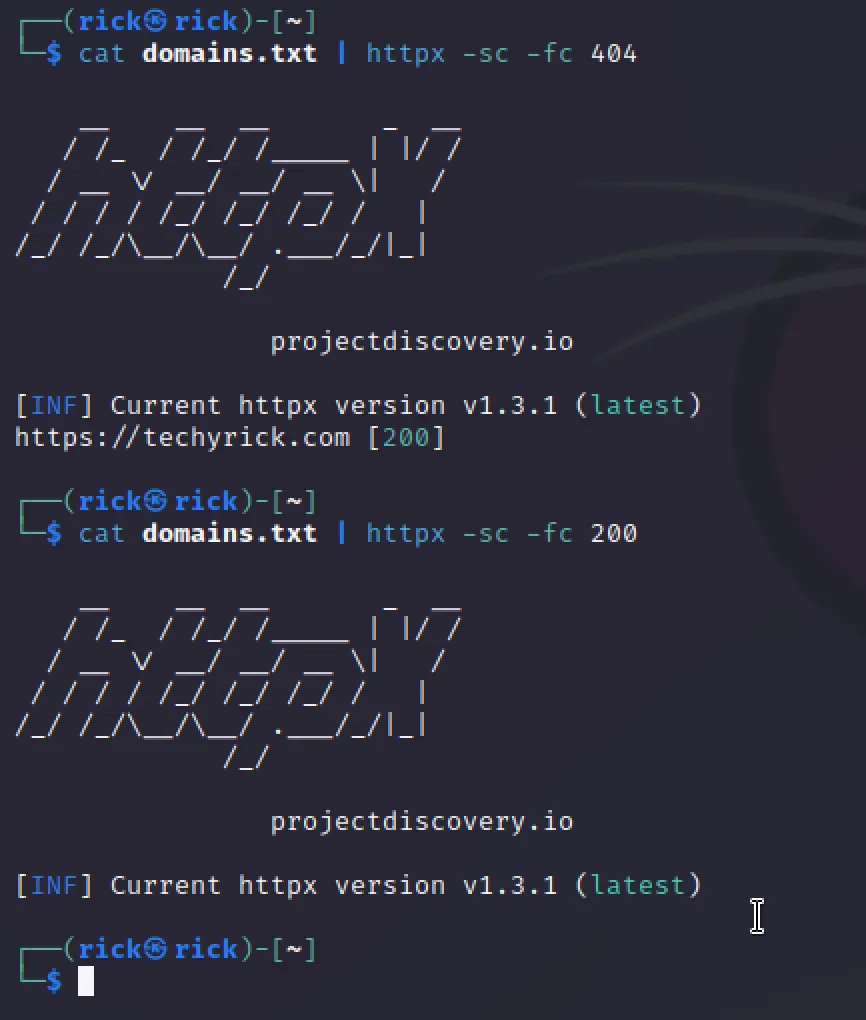
- -fl: filters content length.
- -fwc: filters the word count.
- -flc: filter line count.
- -fs: filter the output with the provided string.
- -ffc: favicon filter.
Let’s try the favicon filter ????
cat domains.txt | httpx -sc -ffc 200
Just give a try on it ❤️
Threads
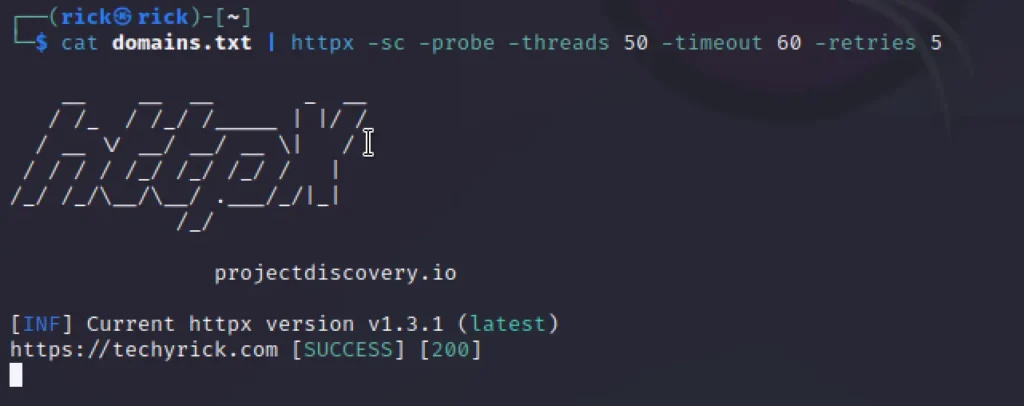
In httpx we can add threads, timeout and retries, All the three are having unique features.
- -t: specify the number of threads used for the scan. Can be as high as 150. Default 50.
- -rl: specifies the rate limit in requests per second
- -rlm: specifies the rate limit in requests per minute
- -timeout: To abort the scan in specified seconds
- -retries: Number of retries before aborting the scan
cat domains.txt | httpx -sc -probe -threads 50 -timeout 60 -retries 5
Filtering SQL and XSS
As we are aware, some forms of SQL injections are reflected in the code output.
To detect such injections, we can filter the output of a web page. In error-based SQLi, an error is actually thrown and subsequently appears in the output page.
As illustrated in the command below, we have implemented the -ms filter to compare and identify these pages.
Essentially, an attacker can supply a list of inputs and discover common SQLi vulnerabilities in a comparable manner.
echo "http://techyrick.com" | httpx -path "/listproducts.php?cat=1’" -ms "Error: You have an error in your SQL syntax;"
echo "http://testphp.vulnweb.com" | httpx -path "/listproducts.php?cat=<script>alert(1)</script>" -ms "<script>alert(1)</script>"

Web Fuzzing
Web fuzzing in httpx is really great below is how to do directory fuzzing.
echo "http://techyrick.com" | httpx -probe -sc -path "/login.php"
Specify the -p and the parma to do web fuzzing with default wordlists from httpx, Below is the web fuzzing results.

Conclusion
In this post, We have seen how to use httpx, It’s a great tool even though the curl is able to do all the above features, The httpx is unique among bug bounty hunters and it’s popular.

